In this article, we will look at the basics of Distributed SQL. In 2012, Google’s spanner has coined the concept of Distributed SQL databases.
What is Distributed SQL?
Its single relational database deployed on a cluster of network servers. It automatically replicates and distributes data among the server nodes. It is strongly consistent and provides ACID transactional support. It uses Paxo’s or Raft algorithm to achieve consensus across multiple nodes.
Compared to NewSQL?
Distributed databases are sometimes referred as NewSQL but NewSQL contains databases that are not distributed databases. Its more specific subset of NewSQL
Features of Distributed SQL:
- A robust SQL API for accessing and manipulating data and objects
- Automatic data distribution & data replication in a strongly consistent manner across nodes
- Distributed query execution
- Distributed ACID transactions
- Resilient to failures
- Scales horizontally to support workload increases and decreases
- Supports geo-distributed cluster topology to deliver consistent experience
- Follows CAP theorem – CP: Consistent and partition -tolerant
Architecture:
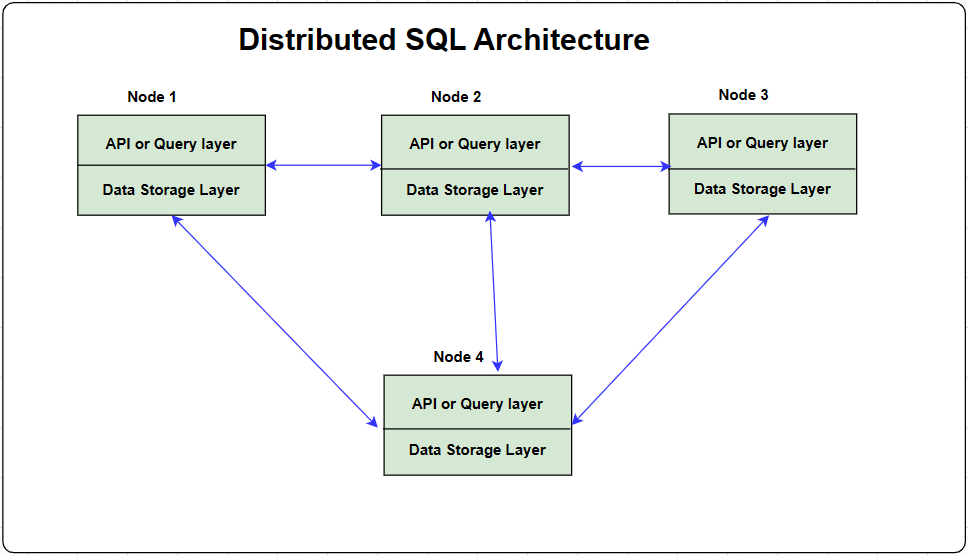
Distributed SQL consists of two layers
- API /Query Layer
This does the processing of the queries. API layer does the support to model relational data & perform queries against those relational queries.
- Data Storage Layer
This does the replication of data across multiple nodes in a cluster to ensure high availability & performance.
It supports distributed ACID transactions which allows modification of multiple data across multiple nodes to ensure data integrity.
Few of the Dynamic SQL databases
- Cockroach DB
- YugaByte DB
- VuoDB
- Amazon Aurora
- Terradata
- Google Spanner