In this article, we will look at the basics of Hadoop and its ecosystem. It’s an open-source framework written in Java and developed by Doug Cutting in 2005. It enables processing of large data sets which is not handled efficiently by traditional methodologies like RDBMS (Relational Database Management System).
What is Hadoop?
Hadoop framework meant to process large datasets and not for small datasets. Its not replacement of RDBMS. It handles processing of variety of data: Structured, semi-structured and unstructured data using hardware which are inexpensive. It has high throughput and response time won’t be immediate as its batch operation handling large datasets.
Why Hadoop is required?
Earlier processing of data is faster with single processer & storage unit as generation of data was not high. With multiple devices & every day millions/trillions of data is generated, conventional systems will not be able to process quickly for large datasets that too with variety of data. To address this issue, Hadoop was developed to store & process huge volume of data fastly
Advantages of Hadoop:
- Stores data in Native Format
It stores data in native format & its schema-less. Its
- Flexibility
It handles variety of data: Structured, semi-structured and unstructured
- Scalable
Have the ability to store & distribute data (e.g., TB) across multiple servers that operates
parallelly
- Processing is extremely faster compared to traditional systems
- Fault-Tolerant
It uses replication to copy the data across multiple nodes. If one server goes down, then it
automatically takes data from another server node.
- Cost Reduction
Its very cost – effective for storing & processing large sets of data
Hadoop Ecosystem:
Below diagram illustrates the components of Hadoop Ecosystem. Let’s look at each of the components in detail.
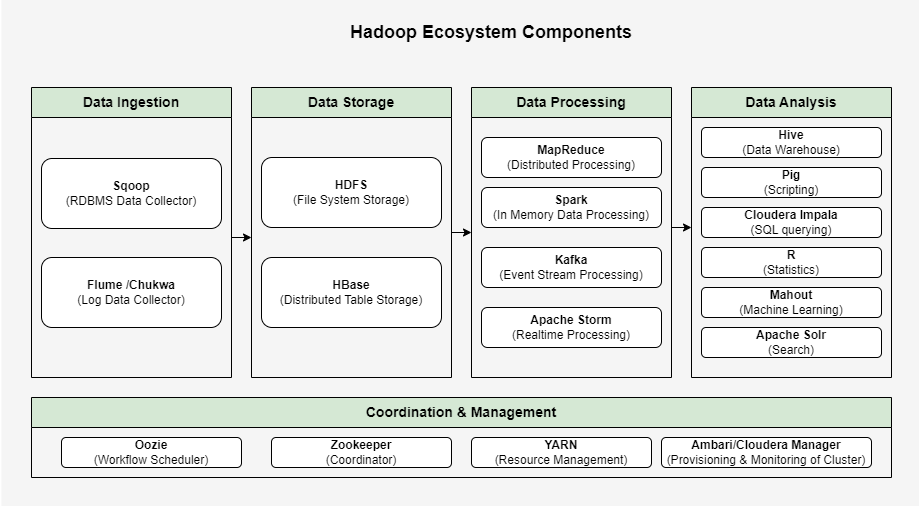
Data Ingestion Component:
- Sqoop
It stands for SQL to Hadoop. It imports data from RDBMS systems (Oracle, MySQL etc) to Hadoop Storage (HDFS, HBase etc) and Vice Versa
- Flume
It is log aggregator component developed by Cloudera . It collects & aggregates logs from different machines and store in the HDFS
- Chukwa
It is Hadoop subproject for large scale log collection and analysis
Data Storage Component:
- HDFS (Hadoop Distributed File System)
It is distributed storage unit in Hadoop and stores files across multiple machines. It is highly fault-tolerant as data stored is redundant
- HBase
It stores data in HDFS. It is database on top of HDFS & provides quick access to the stored data. It is No-SQL database and Columm-Oriented database. It is having low latency compared to HDFS.
Data Processing Component:
- MapReduce
It is based on Google MapReduce. This allows distributed & parallel processing of large datasets. It is having two phases: Map & Reduce. Map will take input from HDFS & convert to key-value pair. Reduce will take output of Map phase & process information to reduce it to smaller set of tuples which is again stored in HDFS.
- Spark
It is programming & computing model. This is written in Scala. It does in memory processing rather than disk processing which is why it’s faster
- Kafka
It is open-source framework for distributed event stream processing of real time feeds. It is written in Java & Scala.
- Apache Storm
It is distributed real time processing open-source framework
Data Analysis Component:
- Pig
It is scripting language used in Hadoop and it is an alternate to MapReduce. This will be helpful for developers who is not comfortable with MapReduce. It has two parts: Pig Latin – SQL like Script, Pig Runtime – Runtime environment. Pig Latin scripts are translated to MapReduce jobs which is then executed in Hadoop environment.
- Hive
It is data warehouse built on top of Hadoop platform. It converts SQL-like scripts to MapReduce jobs
- Cloudera Impala
It is open-source parallel processing SQL query engine used for querying data stored in HDFS, Apache HBase. It has very low latency measured in milliseconds.
- R
It’s used for data visualisation, statistical computation and analysis of data
- Mahout
It is machine learning library used for clustering, classification and collaborative filtering of data.
- Apache Solr
It is open-source search platform used for full-text search, real-time indexing etc
Configuration & Management Components:
- Oozie
It is workflow scheduler for managing Hadoop jobs
- Zookeeper
It is coordinator service for distributed applications
- Ambari
It is web-based tool for provisioning, managing and monitoring Hadoop clusters.
- Cloudera Manager
It is commercial tool created by Cloudera for provisioning, managing and monitoring Hadoop clusters.
- YARN
It stands for ‘Yet Another Resource Negotiator’. It is processing framework in Hadoop which allows multiple data processing engines and provides resource management. It allocates system resources for application running in Hadoop cluster and assign which task to be executed by each cluster nodes.
Hadoop Versions:
There are two versions: Hadoop 1.0 & Hadoop 2.0
Hadoop 1.0:
It has only data storage (HDFS) and data processing (MapReduce) component. With this only batch processing is possible
Hadoop 2.0:
It has data storage (HDFS), YARN (Cluster Resource Management) data processing (MapReduce) component. With this batch & real time processing is possible. YARN allows other data processing engines to run and manages resource allocation.
Hope this article provides basic knowledge about Hadoop and helpful.